
Part 1: Signals and Linux
- Part 1: Signals and Linux [you’re here]
- Part 2: Containers and signals
- Part 3: Graceful shutdown of K8S pods
- Part 4: Celery Graceful Shutdown
- Part 5: Prometheus Graceful Shutdown
- Part 6: Other frameworks and libraries [WIP]
Intro
There’s been quite a lot of issues surrounding application shutdowns in my line of work. Connections not being correctly closed, incoming requests being processed when they shouldn’t have been, various quirks around how new deployments affect customers during busy hours. I’ve decided to familiarize myself more with the topic and that’s quite a lot going on there.
I won’t be able to tell my findings in one blog post as I want to cover it in utter detail, so there will be a series. I will take a basic set-up in the modern world: Django-based application, wrapped up in Docker and running in the K8s deployment together with some Celery workers, all taking place on some Linux box.
I will accompany my train of thought with references and snippets of the actual codebase where feasible. I will go through the latest versions possible of whatever I’m looking at:
I assume the reader is familiar with some very basics: what Linux and Linux kernel are, able to read briefly the C, Go, and Python codebases, understands the concept of operating system threads and processes, knows what containers, Docker, and k8s are.
Well, what is a graceful shutdown?
In modern deployments, applications are reloaded, restarted, and redeployed constantly. If you want to release a new version of your web application, you must first stop the old one and then run a new one. Ideally, this should happen unnoticed by your end-user. You don’t want them to know that some vital transaction failed due to someone pushing a new software version, do you?
Also, modern applications are often monstrous in terms of what they need to do. Imagine your Django application: it has to handle incoming HTTP requests, talk to the database, usually talk to the RabbitMQ to schedule async tasks, publish some stuff into the Kafka, communicate with other systems via HTTP, etc.
As the developer, you want to be sure that in general case execution of your code is not interrupted mid-term request processing, so you’re able to write code (pseudo-code, of course) like this:
def some_controller(request):
user = authenticate_user_via_db(request)
schedule_some_task.delay(user.id)
send_analytics_via_kafka(some_event(user))
call_other_microservice_via_http(user.id)
return Response({})
Looks pretty straightforward, but a lot of hidden machinery needs to work correctly.

Your app needs to handle multiple connection pools and open sockets to the client, and this machinery should not, in general, be stopped suddenly (or you may face resource leaks and customer-facing problems).
So to prevent this, an idea of a graceful shutdown exists: when some orchestrator decides that it is time for the app to go, it sends two signals: one telling the app to finish up processing whatever it is working on, and, after some period if it did not help - a termination signal that can not be stopped and kills the app entirely at whatever point it is.
Wait, signals?
Yeap, signals. A signal is a form of inter-process communication, a way for one process or an OS kernel to deliver some action to another process. Beware, we’re covering only the Linux kernel and POSIX signals.
We’re interested in two signals in the context of graceful shutdowns: SIGTERM and SIGKILL.
A SIGTERM signal is typically sent to the process to tell it “it’s time to leave the Earth, clean up after yourself.”. A SIGKILL is something that forcefully kills your running process w/o any doubts (well, except for some pending IO kernel tasks). A moment between getting SIGTERM and getting killed is where the clean-up part of your application should happen.
If you want to play with it, you may open two terminal tabs and run this in one tab:
python -c "import time, os; print(os.getpid()); time.sleep(100000)"
This will run the Python interpreter, print out the PID, and wait some time.
In another terminal tab you may run the following command:
kill <pid-of-the-python-interpeter>
You will see the first process gets terminated. For experiment’s sake, try running the python process via the sudo and see how an unprivileged process can not send a signal to the super-user run process.
Kill command is the utility that sends signals (by default a SIGTERM one) to the specified process.
But we’re in the post named Anatomy of graceful shutdown, so let’s follow what happens inside the kill software.
Inside the victim
But what does it give us? Yeah, we can send some signals but we’re talking about graceful shutdowns, right?
We need to do something about them as well. Typically, language standard libraries allow you to register some callback to the signal handler.
Here are some examples.
Python
import signal
import socket
from selectors import DefaultSelector, EVENT_READ
from http.server import HTTPServer, SimpleHTTPRequestHandler
interrupt_read, interrupt_write = socket.socketpair()
def handler(signum, frame):
print('Signal handler called with signal', signum)
interrupt_write.send(b'\0')
signal.signal(signal.SIGINT, handler)
signal.signal(signal.SIGTERM, handler)
def serve_forever(httpd):
sel = DefaultSelector()
sel.register(interrupt_read, EVENT_READ)
sel.register(httpd, EVENT_READ)
while True:
for key, _ in sel.select():
if key.fileobj == interrupt_read:
interrupt_read.recv(1)
return
if key.fileobj == httpd:
httpd.handle_request()
print("Serving on port 8000")
httpd = HTTPServer(('', 8000), SimpleHTTPRequestHandler)
serve_forever(httpd)
print("Shutdown...")
Go
package main
import (
"context"
"fmt"
"log"
"net/http"
"os"
"os/signal"
"syscall"
)
func run_server(ctx context.Context, addr string) error {
ctx, cancel := signal.NotifyContext(ctx, syscall.SIGTERM, syscall.SIGINT)
defer cancel()
srv := &http.Server{Addr: addr}
go func() {
<-ctx.Done()
srv.Shutdown(context.Background())
}()
return srv.ListenAndServe()
}
func main() {
ctx := context.Background()
fmt.Printf("Server is running as PID %d\n", os.Getpid())
if err := run_server(ctx, ":8080"); err != nil {
log.Fatalf("Server failed: %v", err)
os.Exit(1)
}
}
C
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
void int_handler(int sig, siginfo_t *info, void *ucontext)
{
printf("Handler called for signal %d, with code %d\n", sig, info->si_code);
}
int main(void)
{
struct sigaction action;
action.sa_flags = SA_SIGINFO;
action.sa_sigaction = int_handler;
sigaction(SIGTERM, &action, NULL);
printf("Running the process with PID: %d\n", getpid());
while (1)
{
sleep(1);
}
return EXIT_SUCCESS;
}
Bash
function cleanup()
{
echo "Caught Signal ... cleaning up."
exit 0
}
trap cleanup SIGINT SIGTERM
while true
do
echo Sleeping
sleep 10
done
This signal handler is generally used on the application side to clean up resources for the process lifecycle.
Different languages provide different API’s for setting a signal handler, but, in general, most of them (scripting languages are the exception, due to the way their virtual machines and transalation from the VM code and underlying system APIs work) result in sigaction underlying API call. This call will modify process internal structures to point to the function to be called on the signal delivery.
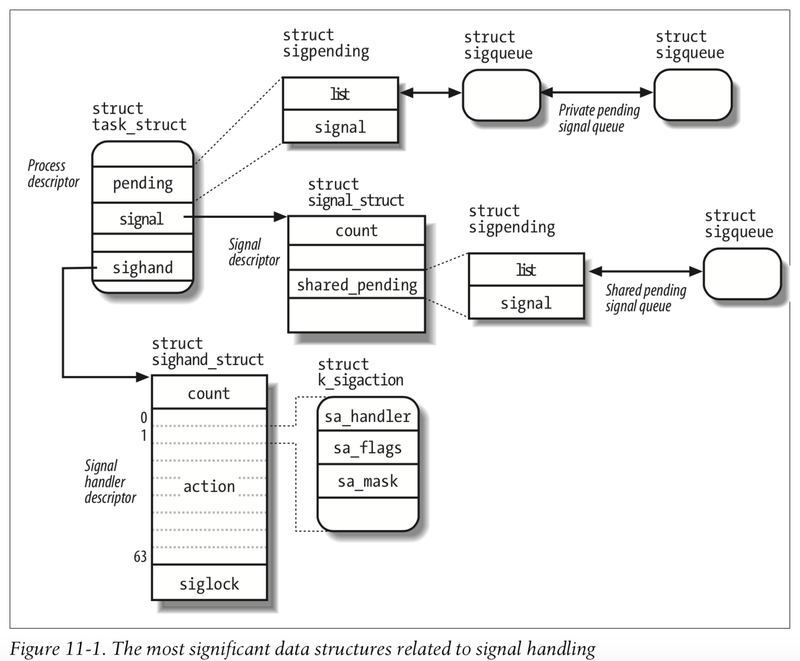
Kernel signal data structures
Linux processes (and threads as well) are represented by a task_struct C-structure. It’s a large data structure containing all of the required fields and pointers to functions and other data structures critical for process scheduling and execution.
/* https://elixir.bootlin.com/linux/v6.7.4/source/include/linux/sched.h#L1107 */
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct __rcu *sighand;
sigset_t blocked;
sigset_t real_blocked;
/* Restored if set_restore_sigmask() was used: */
sigset_t saved_sigmask;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;
The best illustration of related kernel data structures, as well as a lot of internals explanation, can be found in the amazing Linux Kernel Internals book.
Inside the killer mind
So, we’ve looked at what happens on the signal receiver side. We’ve also mentioned the kill command to send signals. But what happens from the kernel perspective when the command is used?
The source code for the kill utility (as well as a bunch of others) can be found in this repo. It is really compact and easy to follow.
int main(int argc, char **argv)
{
// ommitted set-up and argument parsing
for ( ; (ctl.arg = *argv) != NULL; argv++) {
char *ep = NULL;
errno = 0;
ctl.pid = strtol(ctl.arg, &ep, 10);
if (errno == 0 && ep && *ep == '\0' && ctl.arg < ep) {
// Check whether user-space signal handler is defined by process
if (check_signal_handler(&ctl) <= 0)
continue;
// Perform actual signal sending
if (kill_verbose(&ctl) != 0)
nerrs++;
ct++;
} else {
// omitted Logic related to process group handling
}
}
}
if (ct && nerrs == 0)
return EXIT_SUCCESS; /* full success */
if (ct == nerrs)
return EXIT_FAILURE; /* all failed */
return KILL_EXIT_SOMEOK; /* partial success */
}
There’s some initial CMD args processing and structures set-up, which results in the kill() API being called.
static int kill_verbose(const struct kill_control *ctl)
{
int rc = 0;
if (ctl->verbose)
printf(_("sending signal %d to pid %d\n"), ctl->numsig, ctl->pid);
if (ctl->do_pid) {
printf("%ld\n", (long) ctl->pid);
return 0;
}
#ifdef UL_HAVE_PIDFD
if (ctl->timeout) {
rc = kill_with_timeout(ctl);
} else
#endif
#ifdef HAVE_SIGQUEUE
if (ctl->use_sigval)
rc = sigqueue(ctl->pid, ctl->numsig, ctl->sigdata);
else
#endif
rc = kill(ctl->pid, ctl->numsig);
if (rc < 0)
warn(_("sending signal to %s failed"), ctl->arg);
return rc;
}
🤔
Kill utility leads us to the kill function being called.

Well, let’s dive deeper. But where does this function come from? It comes from the glibc, an implementation of the standard library for C.
We need to find out where we can find the implementation. Let’s try some like with the old good man:
man 2 kill
And here we find something useful:
NAME
kill – send signal to a process
SYNOPSIS
#include <signal.h>
int
kill(pid_t pid, int sig);
DESCRIPTION
The kill() function sends the signal specified by sig to pid, a process or a group of processes. Typically, Sig
will be one of the signals specified in sigaction(2). A value of 0, however, will cause error checking to be
performed (with no signal being sent). This can be used to check the validity of pid.
That’s the point I failed to find the source code for the kill function implementation in the glibc codebase facing this definition in signal.h.
extern int kill (__pid_t __pid, int __sig) __THROW;
Hmm.
Syscalls
Let’s look at what happens in terms of syscalls when we invoke our kill utility.
sudo strace kill <pid>
execve("/usr/bin/kill", ["kill", "218716"], 0x7fdfdbac58 /* 30 vars */) = 0
brk(NULL) = 0x556e19b000
faccessat(AT_FDCWD, "/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=31299, ...}) = 0
mmap(NULL, 31299, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f970bb000
...
A LOT OF SYSCALLS WE'RE NOT REALLY INTERESTED IN
...
openat(AT_FDCWD, "/usr/share/locale/en/LC_MESSAGES/procps-ng.mo", O_RDONLY) = -1 ENOENT (No such file or directory)
kill(218716, SIGTERM) = 0
close(1) = 0
close(2) = 0
exit_group(0) = ?
What did we do? We’ve run the strace utility to see, what kind of system calls the program makes. You may ask: what the heck is a system call? It’s quite a long topic, and I’m no systems programming expert, but basically, it is a way for your userspace program to request some privileged action from the OS kernel, that require privilege escalation (IO, IPC, memory operations and on and on and on).
And we definitely see the kill syscall being requested by the kill utility, which we’ve seen before in our man pages.
Nice.
Kernel behavior
Signals
But we need to go deeper. How do we find what Kernel does when syscall is being invoked by the program?
Well, that’s a difficult question. There’s a beautiful book Linux-Insides that gives a very in-depth overview of what happens in the Kernel in general (specifically here).
We can find a table of syscalls here
60 common exit sys_exit
61 common wait4 sys_wait4
62 common kill sys_kill
63 common uname sys_newuname
Long-story short here’s the definition of the actual sys call
/**
* sys_kill - send a signal to a process
* @pid: the PID of the process
* @sig: signal to be sent
*/
SYSCALL_DEFINE2(kill, pid_t, pid, int, sig)
{
struct kernel_siginfo info;
prepare_kill_siginfo(sig, &info);
return kill_something_info(sig, &info, pid);
}
There’s quite a lot going on with the C preprocessor macroses that is covered in this article and that’s not we’re particularly interested in.
We should understand that the code we’re looking at is executed in the kernel mode and can access process data structures and do everything the privileged code can do.
The signal handling is divided into two parts: delivery and execution.

Signal delivery
Below is the interactive call stack trace (clickable!) the kernel executes to update process structures (down below, you can see the saddest (&pending->signal, sig); call that is responsible for putting a notification to the process signal queue).
That’s, eh, quite a few lines of code we’ve had to trace. There are a lot of checks for specific signals (terminal ones like SIGKILL) happening along the way, but we’ve initially reached a phase where we tell the scheduler that it is time to switch the context of the targeted task (process) to execute a signal.
Signal execution
Signals are invoked when the kernel switches from the kernel mode to the user mode (e.g. after finishing a syscall or on scheduler interrupt). As we’ve seen, the context switch is forced in the previous chapter.
There are several entry points, but let’s follow one of them (syscall invocation).
To be honest, that’s where my journey stalled. I found the code responsible for actual signal finding in the process data structure and presumable execution of the handler. Comments imply the code should be run precisely here:
ka = &sighand->action[signr-1];
/* Trace actually delivered signals. */
trace_signal_deliver(signr, &ksig->info, ka);
if (ka->sa.sa_handler == SIG_IGN) /* Do nothing. */
continue;
if (ka->sa.sa_handler != SIG_DFL) {
/* Run the handler. */
ksig->ka = *ka;
if (ka->sa.sa_flags & SA_ONESHOT)
ka->sa.sa_handler = SIG_DFL;
break; /* will return non-zero "signr" value */
}
but I was unable to find the actual execution. My assumption is that because we’ve set up process registers, when the expected user-space execution proceeds, the execution will be forced to start at the specified signal handler, but that’s just speculation.
int setup_signal_stack_si(unsigned long stack_top, struct ksignal *ksig,
struct pt_regs *regs, sigset_t *mask)
{
struct rt_sigframe __user *frame;
void __user *restorer;
int err = 0, sig = ksig->sig;
stack_top &= -8UL;
frame = (struct rt_sigframe __user *) stack_top - 1;
if (!access_ok(frame, sizeof(*frame)))
return 1;
restorer = frame->retcode;
if (ksig->ka.sa.sa_flags & SA_RESTORER)
restorer = ksig->ka.sa.sa_restorer;
err |= __put_user(restorer, &frame->pretcode);
err |= __put_user(sig, &frame->sig);
err |= __put_user(&frame->info, &frame->pinfo);
err |= __put_user(&frame->uc, &frame->puc);
err |= copy_siginfo_to_user(&frame->info, &ksig->info);
err |= copy_ucontext_to_user(&frame->uc, &frame->fpstate, mask,
PT_REGS_SP(regs));
/*
* This is movl $,%eax ; int $0x80
*
* WE DO NOT USE IT ANY MORE! It's only left here for historical
* reasons and because gdb uses it as a signature to notice
* signal handler stack frames.
*/
err |= __put_user(0xb8, (char __user *)(frame->retcode+0));
err |= __put_user(__NR_rt_sigreturn, (int __user *)(frame->retcode+1));
err |= __put_user(0x80cd, (short __user *)(frame->retcode+5));
if (err)
return err;
PT_REGS_SP(regs) = (unsigned long) frame;
PT_REGS_IP(regs) = (unsigned long) ksig->ka.sa.sa_handler;
PT_REGS_AX(regs) = (unsigned long) sig;
PT_REGS_DX(regs) = (unsigned long) &frame->info;
PT_REGS_CX(regs) = (unsigned long) &frame->uc;
return 0;
}
As you can see here, we adjust stack frames and provide a function to be called after the signal is invoked to restore the normal process stack.
I’d be really grateful if anyone could point me to where the handler code is executed.
Summary
Hey there, once again. The wall of text above may seem intimidating, so let’s have a short recap of what we’ve known.
Graceful shutdown is the way modern systems ask processes to clean up their resources before they get completely terminated by the operating systems (as termination happens suddenly and deterministically).
One of the common ways to achieve graceful shutdowns is to rely upon the signaling mechanism of the kernel: a form of interprocess communication where one process (part of some scheduler, e.g., K8S) can send a signal (usually SIGTERM) to another process for it to finish-up its deeds.
There’s also a way for the process to react to signals and run their routines to perform some clean-up.
This machinery on the low level is managed by the OS kernel. Sending signals allocates special data structures in the operating system process. When the notified process is returned to the user-mode, its signal queues are checked, and if conditions are met - appropriate signal handlers are invoked.
SIGKILL can not be blocked or processed; it is handled by the default logic that kills the process and its children threads.
In the following article, we’ll look at how Docker and K8S use signals to implement graceful shutdowns of apps; stay tuned!
References
- Amazing reading on problems with signals in Rust
- https://cpu.land/lets-talk-about-forks-and-cows
- https://github.com/0xAX/linux-insides/blob/master/SysCall/linux-syscall-4.md
- https://man7.org/linux/man-pages/man7/signal.7.html
- https://linux-kernel-labs.github.io/refs/heads/master/lectures/syscalls.html
- https://helix979.github.io/jkoo/post/os-scheduler/
- https://www.quora.com/How-are-signals-implemented-in-Linux
- https://liujunming.top/2018/12/29/Understanding-the-Linux-Kernel-%E8%AF%BB%E4%B9%A6%E7%AC%94%E8%AE%B0-Signals/
- https://unix.stackexchange.com/questions/485644/what-does-a-program-do-when-its-sent-sigkill-signal/485657#485657
- https://grafana.com/blog/2024/02/09/how-i-write-http-services-in-go-after-13-years/