A short exploration of what Docker, containerd, runc are today. How they comprise a modern container stack, how they implement a management of graceful shutdowns, how linux signals are handled within the containerized docker apps.
The previous chapter was difficult, and I assumed things would get easier along the way. Little did I know. Instead of discussing the actual graceful shutdown topic, this post will focus more on the overview of the modern state of containers application.
If you’ve been developing and deploying web applications recently, you’ve likely stumbled upon containerization. It’s a very convenient way to package and ship your applications in a reproducible, compact, and quite simple fashion. You write down a Dockerfile, defining steps to install required dependencies, your CI builds the image, it then gets shipped to some staging environment and then reaches your holy grail production cluster (running the Kubernetes, Rancher, Nomad, or other orchestration platform of choice).
If you have Docker installed you may become a little bit of the orchestrator yourself:
You’ve just created a running Nginx container, gracefully shut it down, and removed it. Basically did a thing your Kubernetes cluster does all day (but not using the Docker CLI, of course).
If you still remember, we’re exploring the topic of graceful shutdown, and what we’re interested in is what happens within containers. That’s quite a challenging topic to explore as it is constantly evolving. Docker has been here for more than 10 years and has undergone many changes in its internal architecture and usage by other platforms.
As of now, it is not technically correct to put an equality sign between Docker and the container technology for someone who’s been using Docker technology for all these years.
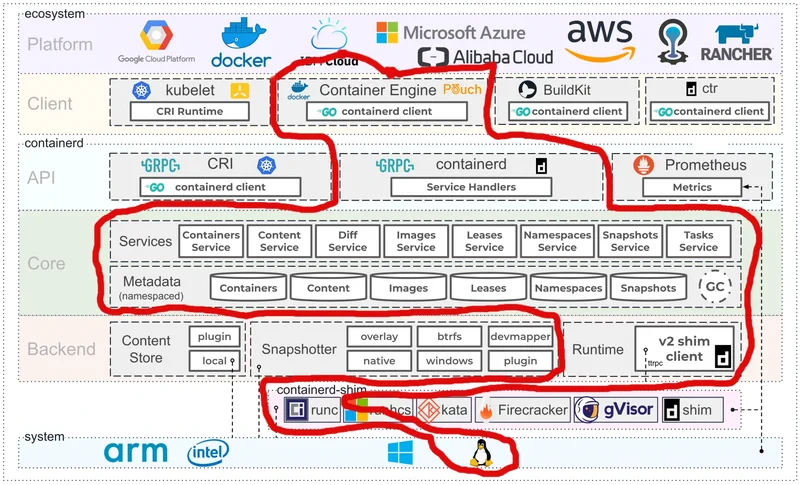
To understand what I’m talking about, let’s take a look at the architecture of the Docker software that may run on your client machine (I took it from the website as the most extensive picture I could find):
From here, you can see that containerization and orchestration is very layered with a bunch of moving stuff:
Containers on Linux rely upon kernel’s cGroups and namespaces, providing capabilities to isolate and impose limits for processes. Those are system-level APIs allowing you to create independent process hierarchies (so that each container can have it’s own PID 1), user/group segregation (each container may have its own matching users that do not conflict with each other), memory and CPU allocation policies (to control how much resources specific containers may take) and some other ones.
The low-level details of how to start and stop containers are delegated to a separate layer.
Not to go into a lot of details (that may remind you of OpenAI legal entities relationships) there’s an open governance structure called the Open Container Initiative that develops a standard of what is container and how it should be run, packaged, and distributed.
That’s the part we’re mostly interested in, it’s standard de-facto implementation is called runc, written in Go, and contains OCI spec parser/validator and actual wrappers around aforementioned cGroups and Namespacing capabilities in Linux.
There are some other implementations (of course they are), most notably:
If runc is used to spin up processes, we also need to communicate with them (e.g. track the state, attach to pTTY, read logs) - for this a containerd-shim exists. Each docker container has an associated shim process running.
For example, here’s how my ps axfo pid,ppid,command sees the docker container running:
Given the complexity of container internals, let’s focus on something simple. Let’s discover how the docker stop command works and what is required to stop the running container gracefully.
$ docker version
Client: Docker Engine - Community
Version: 25.0.4
API version: 1.44
OS/Arch: linux/arm64
Server: Docker Engine - Community
Engine:
Version: 25.0.4
API version: 1.44 (minimum version 1.24) Go version: go1.21.8
containerd:
Version: 1.6.28
runc:
Version: 1.1.12
docker-init:
Version: 0.19.0
uname -a
Linux home 5.10.110-rockchip-rk3588 #23.02.2 SMP Fri Feb 17 23:59:20 UTC 2023 aarch64 GNU/Linux
Let’s follow the example from the beginning of the article:
We need a lot of patience here, as following the codebase is not an easy task due to many layers of abstraction, gRPC calls between components and many go-lang interfaces that do not make following the exact code easily.
funcmain(){dockerCli,err:=command.NewDockerCli()iferr!=nil{fmt.Fprintln(os.Stderr,err)os.Exit(1)}logrus.SetOutput(dockerCli.Err())iferr:=runDocker(dockerCli);err!=nil{ifsterr,ok:=err.(cli.StatusError);ok{ifsterr.Status!=""{fmt.Fprintln(dockerCli.Err(),sterr.Status)}// StatusError should only be used for errors, and all errors should// have a non-zero exit status, so never exit with 0ifsterr.StatusCode==0{os.Exit(1)}os.Exit(sterr.StatusCode)}fmt.Fprintln(dockerCli.Err(),err)os.Exit(1)}}
funcrunDocker(dockerCli*command.DockerCli)error{tcmd:=newDockerCommand(dockerCli)cmd,args,err:=tcmd.HandleGlobalFlags()iferr!=nil{returnerr}iferr:=tcmd.Initialize();err!=nil{returnerr}varenvs[]stringargs,os.Args,envs,err=processAliases(dockerCli,cmd,args,os.Args)iferr!=nil{returnerr}ifcli.HasCompletionArg(args){// We add plugin command stubs early only for completion. We don't// want to add them for normal command execution as it would cause// a significant performance hit.err=pluginmanager.AddPluginCommandStubs(dockerCli,cmd)iferr!=nil{returnerr}}iflen(args)>0{ccmd,_,err:=cmd.Find(args)iferr!=nil||pluginmanager.IsPluginCommand(ccmd){err:=tryPluginRun(dockerCli,cmd,args[0],envs)if!pluginmanager.IsNotFound(err){returnerr}// For plugin not found we fall through to// cmd.Execute() which deals with reporting// "command not found" in a consistent way.}}// We've parsed global args already, so reset args to those// which remain.cmd.SetArgs(args)returncmd.Execute()}
funcnewDockerCommand(dockerCli*command.DockerCli)*cli.TopLevelCommand{var(opts*cliflags.ClientOptionshelpCmd*cobra.Command)cmd:=&cobra.Command{Use:"docker [OPTIONS] COMMAND [ARG...]",Short:"A self-sufficient runtime for containers",SilenceUsage:true,SilenceErrors:true,TraverseChildren:true,RunE:func(cmd*cobra.Command,args[]string)error{iflen(args)==0{returncommand.ShowHelp(dockerCli.Err())(cmd,args)}returnfmt.Errorf("docker: '%s' is not a docker command.\nSee 'docker --help'",args[0])},PersistentPreRunE:func(cmd*cobra.Command,args[]string)error{returnisSupported(cmd,dockerCli)},Version:fmt.Sprintf("%s, build %s",version.Version,version.GitCommit),DisableFlagsInUseLine:true,CompletionOptions:cobra.CompletionOptions{DisableDefaultCmd:false,HiddenDefaultCmd:true,DisableDescriptions:true,},}cmd.SetIn(dockerCli.In())cmd.SetOut(dockerCli.Out())cmd.SetErr(dockerCli.Err())opts,helpCmd=cli.SetupRootCommand(cmd)_=registerCompletionFuncForGlobalFlags(dockerCli.ContextStore(),cmd)cmd.Flags().BoolP("version","v",false,"Print version information and quit")setFlagErrorFunc(dockerCli,cmd)setupHelpCommand(dockerCli,cmd,helpCmd)setHelpFunc(dockerCli,cmd)cmd.SetOut(dockerCli.Out())commands.AddCommands(cmd,dockerCli)cli.DisableFlagsInUseLine(cmd)setValidateArgs(dockerCli,cmd)// flags must be the top-level command flags, not cmd.Flags()returncli.NewTopLevelCommand(cmd,dockerCli,opts,cmd.Flags())}
funcAddCommands(cmd*cobra.Command,dockerClicommand.Cli){cmd.AddCommand(// commonly used shorthandscontainer.NewRunCommand(dockerCli),container.NewExecCommand(dockerCli),container.NewPsCommand(dockerCli),image.NewBuildCommand(dockerCli),image.NewPullCommand(dockerCli),image.NewPushCommand(dockerCli),image.NewImagesCommand(dockerCli),registry.NewLoginCommand(dockerCli),registry.NewLogoutCommand(dockerCli),registry.NewSearchCommand(dockerCli),system.NewVersionCommand(dockerCli),system.NewInfoCommand(dockerCli),// management commandsbuilder.NewBuilderCommand(dockerCli),checkpoint.NewCheckpointCommand(dockerCli),container.NewContainerCommand(dockerCli),context.NewContextCommand(dockerCli),image.NewImageCommand(dockerCli),manifest.NewManifestCommand(dockerCli),network.NewNetworkCommand(dockerCli),plugin.NewPluginCommand(dockerCli),system.NewSystemCommand(dockerCli),trust.NewTrustCommand(dockerCli),volume.NewVolumeCommand(dockerCli),// orchestration (swarm) commandsconfig.NewConfigCommand(dockerCli),node.NewNodeCommand(dockerCli),secret.NewSecretCommand(dockerCli),service.NewServiceCommand(dockerCli),stack.NewStackCommand(dockerCli),swarm.NewSwarmCommand(dockerCli),// legacy commands may be hiddenhide(container.NewAttachCommand(dockerCli)),hide(container.NewCommitCommand(dockerCli)),hide(container.NewCopyCommand(dockerCli)),hide(container.NewCreateCommand(dockerCli)),hide(container.NewDiffCommand(dockerCli)),hide(container.NewExportCommand(dockerCli)),hide(container.NewKillCommand(dockerCli)),hide(container.NewLogsCommand(dockerCli)),hide(container.NewPauseCommand(dockerCli)),hide(container.NewPortCommand(dockerCli)),hide(container.NewRenameCommand(dockerCli)),hide(container.NewRestartCommand(dockerCli)),hide(container.NewRmCommand(dockerCli)),hide(container.NewStartCommand(dockerCli)),hide(container.NewStatsCommand(dockerCli)),hide(container.NewStopCommand(dockerCli)),hide(container.NewTopCommand(dockerCli)),hide(container.NewUnpauseCommand(dockerCli)),hide(container.NewUpdateCommand(dockerCli)),hide(container.NewWaitCommand(dockerCli)),hide(image.NewHistoryCommand(dockerCli)),hide(image.NewImportCommand(dockerCli)),hide(image.NewLoadCommand(dockerCli)),hide(image.NewRemoveCommand(dockerCli)),hide(image.NewSaveCommand(dockerCli)),hide(image.NewTagCommand(dockerCli)),hide(system.NewEventsCommand(dockerCli)),hide(system.NewInspectCommand(dockerCli)),)}
funcNewStopCommand(dockerClicommand.Cli)*cobra.Command{varoptsstopOptionscmd:=&cobra.Command{Use:"stop [OPTIONS] CONTAINER [CONTAINER...]",Short:"Stop one or more running containers",Args:cli.RequiresMinArgs(1),RunE:func(cmd*cobra.Command,args[]string)error{opts.containers=argsopts.timeoutChanged=cmd.Flags().Changed("time")returnrunStop(cmd.Context(),dockerCli,&opts)},Annotations:map[string]string{"aliases":"docker container stop, docker stop",},ValidArgsFunction:completion.ContainerNames(dockerCli,false),}flags:=cmd.Flags()flags.StringVarP(&opts.signal,"signal","s","","Signal to send to the container")flags.IntVarP(&opts.timeout,"time","t",0,"Seconds to wait before killing the container")returncmd}
func(cli*Client)ContainerStop(ctxcontext.Context,containerIDstring,optionscontainer.StopOptions)error{query:=url.Values{}ifoptions.Timeout!=nil{query.Set("t",strconv.Itoa(*options.Timeout))}ifoptions.Signal!=""{// Make sure we negotiated (if the client is configured to do so),// as code below contains API-version specific handling of options.//
// Normally, version-negotiation (if enabled) would not happen until// the API request is made.iferr:=cli.checkVersion(ctx);err!=nil{returnerr}ifversions.GreaterThanOrEqualTo(cli.version,"1.42"){query.Set("signal",options.Signal)}}resp,err:=cli.post(ctx,"/containers/"+containerID+"/stop",query,nil,nil)ensureReaderClosed(resp)returnerr}
func(daemon*Daemon)ContainerStop(ctxcontext.Context,namestring,optionscontainertypes.StopOptions)error{ctr,err:=daemon.GetContainer(name)iferr!=nil{returnerr}if!ctr.IsRunning(){// This is not an actual error, but produces a 304 "not modified"// when returned through the API to indicates the container is// already in the desired state. It's implemented as an error// to make the code calling this function terminate early (as// no further processing is needed).returnerrdefs.NotModified(errors.New("container is already stopped"))}err=daemon.containerStop(ctx,ctr,options)iferr!=nil{returnerrdefs.System(errors.Wrapf(err,"cannot stop container: %s",name))}returnnil}
func(daemon*Daemon)containerStop(ctxcontext.Context,ctr*container.Container,optionscontainertypes.StopOptions)(retErrerror){// Cancelling the request should not cancel the stop.ctx=compatcontext.WithoutCancel(ctx)if!ctr.IsRunning(){returnnil}var(stopSignal=ctr.StopSignal()stopTimeout=ctr.StopTimeout())ifoptions.Signal!=""{sig,err:=signal.ParseSignal(options.Signal)iferr!=nil{returnerrdefs.InvalidParameter(err)}stopSignal=sig}ifoptions.Timeout!=nil{stopTimeout=*options.Timeout}varwaittime.DurationifstopTimeout>=0{wait=time.Duration(stopTimeout)*time.Second}deferfunc(){ifretErr==nil{daemon.LogContainerEvent(ctr,events.ActionStop)}}()// 1. Send a stop signalerr:=daemon.killPossiblyDeadProcess(ctr,stopSignal)iferr!=nil{wait=2*time.Second}varsubCtxcontext.Contextvarcancelcontext.CancelFuncifstopTimeout>=0{subCtx,cancel=context.WithTimeout(ctx,wait)}else{subCtx,cancel=context.WithCancel(ctx)}defercancel()ifstatus:=<-ctr.Wait(subCtx,container.WaitConditionNotRunning);status.Err()==nil{// container did exit, so ignore any previous errors and returnreturnnil}iferr!=nil{// the container has still not exited, and the kill function errored, so log the error here:log.G(ctx).WithError(err).WithField("container",ctr.ID).Errorf("Error sending stop (signal %d) to container",stopSignal)}ifstopTimeout<0{// if the client requested that we never kill / wait forever, but container.Wait was still// interrupted (parent context cancelled, for example), we should propagate the signal failurereturnerr}log.G(ctx).WithField("container",ctr.ID).Infof("Container failed to exit within %s of signal %d - using the force",wait,stopSignal)// Stop either failed or container didn't exit, so fallback to kill.iferr:=daemon.Kill(ctr);err!=nil{// got a kill error, but give container 2 more seconds to exit just in casesubCtx,cancel:=context.WithTimeout(ctx,2*time.Second)defercancel()status:=<-ctr.Wait(subCtx,container.WaitConditionNotRunning)ifstatus.Err()!=nil{log.G(ctx).WithError(err).WithField("container",ctr.ID).Errorf("error killing container: %v",status.Err())returnerr}// container did exit, so ignore previous errors and continue}returnnil}
func(daemon*Daemon)killWithSignal(container*containerpkg.Container,stopSignalsyscall.Signal)error{log.G(context.TODO()).Debugf("Sending kill signal %d to container %s",stopSignal,container.ID)container.Lock()defercontainer.Unlock()task,err:=container.GetRunningTask()iferr!=nil{returnerr}varunpauseboolifcontainer.Config.StopSignal!=""&&stopSignal!=syscall.SIGKILL{containerStopSignal,err:=signal.ParseSignal(container.Config.StopSignal)iferr!=nil{returnerr}ifcontainerStopSignal==stopSignal{container.ExitOnNext()unpause=container.Paused}}else{container.ExitOnNext()unpause=container.Paused}if!daemon.IsShuttingDown(){container.HasBeenManuallyStopped=trueiferr:=container.CheckpointTo(daemon.containersReplica);err!=nil{log.G(context.TODO()).WithFields(log.Fields{"error":err,"container":container.ID,}).Warn("error checkpointing container state")}}// if the container is currently restarting we do not need to send the signal// to the process. Telling the monitor that it should exit on its next event// loop is enoughifcontainer.Restarting{returnnil}iferr:=task.Kill(context.Background(),stopSignal);err!=nil{iferrdefs.IsNotFound(err){unpause=falselog.G(context.TODO()).WithError(err).WithField("container",container.ID).WithField("action","kill").Debug("container kill failed because of 'container not found' or 'no such process'")gofunc(){// We need to clean up this container but it is possible there is a case where we hit here before the exit event is processed// but after it was fired off.// So let's wait the container's stop timeout amount of time to see if the event is eventually processed.// Doing this has the side effect that if no event was ever going to come we are waiting a longer period of time unnecessarily.// But this prevents race conditions in processing the container.ctx,cancel:=context.WithTimeout(context.TODO(),time.Duration(container.StopTimeout())*time.Second)defercancel()s:=<-container.Wait(ctx,containerpkg.WaitConditionNotRunning)ifs.Err()!=nil{iferr:=daemon.handleContainerExit(container,nil);err!=nil{log.G(context.TODO()).WithFields(log.Fields{"error":err,"container":container.ID,"action":"kill",}).Warn("error while handling container exit")}}}()}else{returnerrors.Wrapf(err,"Cannot kill container %s",container.ID)}}ifunpause{// above kill signal will be sent once resume is finishediferr:=task.Resume(context.Background());err!=nil{log.G(context.TODO()).Warnf("Cannot unpause container %s: %s",container.ID,err)}}daemon.LogContainerEventWithAttributes(container,events.ActionKill,map[string]string{"signal":strconv.Itoa(int(stopSignal)),})returnnil}
func(e*execProcess)kill(ctxcontext.Context,siguint32,_bool)error{pid:=e.pid.get()switch{casepid==0:returnfmt.Errorf("process not created: %w",errdefs.ErrFailedPrecondition)case!e.exited.IsZero():returnfmt.Errorf("process already finished: %w",errdefs.ErrNotFound)default:iferr:=unix.Kill(pid,syscall.Signal(sig));err!=nil{returnfmt.Errorf("exec kill error: %w",checkKillError(err))}}returnnil}
Well, that’s it. It’s quite anti-climactic compared to the journey we’ve had before following the Linux kernel. We’ve gone through a bunch of codebases, and it simply results in the Unix signal being sent to the underlying container process!
The way of signal delivery may differ: for example, it is possible to use the systemd as the group manager for runs, and it means that SystemD will be responsible for running the containerized process. For this case, containerd/runc will use the DBus instead of direct process manipulation to stop the running unit. This setting, as far as I understand, is going to become the default for the K8S, but I will talk about K8S in the next post.
I can not but recommend an amazing blog by Ivan Belichko that goes in huge details about container internals. When I’ve seen his articles I thought about quitting this whole post, as there are not more details I could add to his content: