
I’m easily addicted. Addictions change, but my current ones are Call of Duty: Modern Warfare 3 multiplayer and Sudoku. Considering the latter, I have a soft spot for the mind-numbness and peace it gives me. It’s just you, numbers, and pretty evident strategies to win.
At some point, I decided that I needed to quit this ugly habit that breaks the lives of millions of people and causes family splits. I had a spare weekend and not a lot of things to do, so I decided the best thing was to make a sudoku solver. I would get a screenshot or a photo of a sudoku puzzle, parse it, solve it, render a solution, get a dopamine boost in the world of excruciating nothingness, and go on with my life.
Sidenote: what is Sudoku?
We need to start with the basics first. What is a Sudoku? Likely, everybody reading this knows it, but it is a simple numbers puzzle. You have a large square comprising 81 smaller squares; each one may be holding the number. There are also nine 3x3 squares inside a larger one. The numbers in each vertical and horizontal row and in single can not repeat and should be digits from 1 to 9. Some of the squares are empty, and the point of the puzzle is for you to guess the rest, following the constraints.
Here’s a mad skills picture: number 8 should be unique in the areas highlighted in red.

There are variations of the puzzle (different field shapes, number of squares, and constraints, but we do not cover them for simplicity’s sake).
Solution design ദ്ദി(˵ •̀ ᴗ - ˵ ) ✧
Every solution begins with the design drawn on the napkin. Here’s mine:
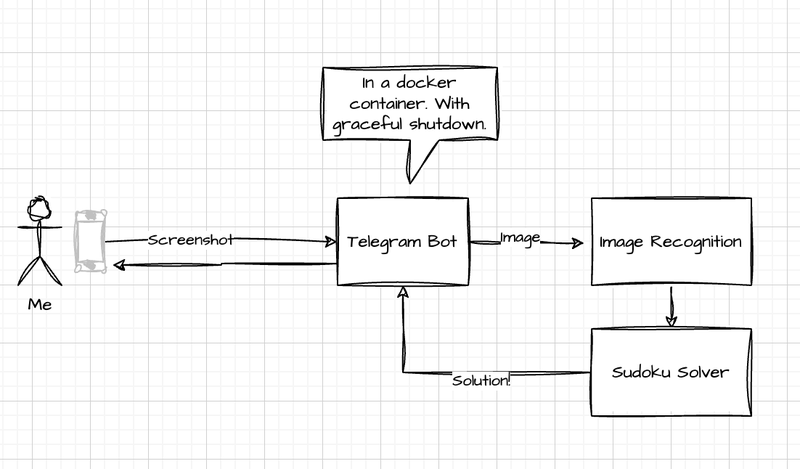
We need a way to interact with the sudoku solver (of course, it is a Telegram bot; there’s just no other way), a recognizer of the Sudoku, and a sudoku solver, and that’s it.
It should be easy and quick!
It was not 🤪. Well, actually, it’s quite easy, but I did not want to simply copy-paste wonderful solutions from the Internet; rather, I wanted to understand them and re-implement them myself! The gray matter goes BR-R-R-R!
How heartless machines solve sudokus?
At first, I decided to code the algorithm for solving a Sudoku all by myself because, well, why not? Then, understanding why hit me, and I decided to do research. By research, I mean going through the top two Google search results, and little do you know the problem is already well-known, well-solved, and well-described by Peter Norvig in his excellent article “Solving Every Sudoku Puzzle” and in a newer ipython-notebook version as well.
The idea behind the scenes is quite simple: it uses the Depth-First Search and the Constraint Propagation/Satisfaction.
We know the constraints of the sudoku puzzle (each digit can only be met once in each row, column, and a 3x3 square), so we recursively go through the Sudoku field in-memory representation, eliminate numbers that are already filled-in and can not be met again and reapply the algorithm recursively. We won if we met all of the constraints and there’s only one possible value for each cell. In case we didn’t - we go back recursively by stack to the stage where it was possible and go on with some other option. If we did not find digits in all iterations and went back to the very beginning - the Sudoku is unsolvable.
You can take a look at my implementation but better take a look at the original work of Peter - it came really clear and simple.
The analysis of the solution, copy-pasting pieces of code, and several re-writes till the moment I found out I’d forgotten to apply constraints before running the actual search took me several hours, but, in the end, I had an interface that looked something like these:
>>> input_str = "..3.2.6..9..3.5..1..18.64....81.29..7.......8..67.82....26.95..8..2.3..9..5.1.3.."
>>> puzzle = Sudoku.from_string(input_str)
>>> solution = puzzle.solve()
>>> print(solution.cli_display())
4 8 3|9 2 1|6 5 7
9 6 7|3 4 5|8 2 1
2 5 1|8 7 6|4 9 3
-----+-----+-----
5 4 8|1 3 2|9 7 6
7 2 9|5 6 4|1 3 8
1 3 6|7 9 8|2 4 5
-----+-----+-----
3 7 2|6 8 9|5 1 4
8 1 4|2 5 3|7 6 9
6 9 5|4 1 7|3 8 2
Sudoku image processing
Field detection
Now comes the part I’m not really familiar with: image recognition. Yeah, I took several machine learning courses back then and did some pet projects for face recognition for a video stream, but that was something I did not really put too much effort into using ready examples (spoiler: that’s about how things went (¬_¬")).
The overall pipeline of image recognition I came up with is as follows:
- Load the image
- Turn it to grayscale and do some Gaussian blur
- Apply Canny edge detection algorith to highlight possible contrast edges in the image
- Apply Contour Detection to extract information about edges
- Locate the largest rectangle on the image (assuming it’s going to be the largest square, i.e. a Sudoku Field)
- Warp the perspective of the found image so that we can reliably extract cells out of it and apply the transformation to make it look flat.
The result of this process is terrifying!
Before:
After

Extracting digits
We now have a square. That’s good. We know the layout of it, so what happens next is just a simple math: we split the square into a set of 81 equal-sized images.
def extract_cells(self, squared_image_path: pathlib.Path, cell_size=50):
# Read the image in grayscale
gray_image = cv2.imread(squared_image_path, cv2.IMREAD_GRAYSCALE)
if gray_image is None:
raise ValueError("Could not load the image, check the path.")
# Assuming the whole image is a Sudoku grid, find the size of the grid
grid_size = gray_image.shape[0] # Assuming the image is a square
# Find the size of each cell
cell_height = grid_size // 9
cell_width = grid_size // 9
# Initialize an array to hold the output cells
cells = np.zeros((81, cell_size, cell_size), dtype=np.uint8)
for i in range(9):
for j in range(9):
# Calculate the starting point of the current cell
y = i * cell_height
x = j * cell_width
cell = gray_image[y : y + cell_height, x : x + cell_width]
cell_resized = cv2.resize(
cell, (cell_size, cell_size), interpolation=cv2.INTER_AREA
)
cells[i * 9 + j] = cell_resized
return cells
Recognizing digits!
MNIST neural networks
We have 81 squares with some possible numbers. We need to understand those numbers and what cells are empty and transform that information to be given to our solver. I assumed that the task of image recognition was so well solved that there were tons of plug-n-play solutions to work with, but I was wrong.
I remembered something about the MNIST dataset and assumed that whatever solves the task the best now would work for me. So I went googling, found some neural network that seemed to recognize the digits the best and followed the instructions to teach my own neural network!
The model
# The model was taken somewhere from Kaggle and I really struggle to find the exact one
# to provide as a reference :(
def create_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (5,5), padding='same', activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(32, (5,5), padding='same', activation='relu'),
tf.keras.layers.MaxPool2D(),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Conv2D(64, (3,3), padding='same', activation='relu'),
tf.keras.layers.Conv2D(64, (3,3), padding='same', activation='relu'),
tf.keras.layers.MaxPool2D(strides=(2,2)),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(num_classes, activation='softmax')
])
model.compile(
optimizer=tf.keras.optimizers.RMSprop(epsilon=1e-08),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)
return model
Learning process
I was inspired and quickly tried it on my data, but I was disappointed. I assumed it would magically recognize Sudoku digits out of the box, but it did not.
Red numbers in the picture represent neural network guesses, black ones that have been originally in the picture.

I played around with image pre-processing, size adjustments and tweaking the image but failed.

Old good OCR
I was disappointed. But I quickly remembered that image recognition was tried out a long time ago and remembered about the existence of OCR solutions like Tesseract and promptly tried this out. But I failed again. I had to play around with its parameters and even with the best pre-processing I could do it failed. I also had to try to run multiple configurations of the recognition choosing whatever worked like this:
def tesseract_image(image) -> int:
"""
BIG BRAIN MOVE
"""
vals = []
configs = [
"-l osd --psm 10 --oem 1",
"--psm 10 --oem 1",
]
for config in configs:
try:
output = pytesseract.image_to_string(image, config=config).strip()
val = int(output[:1])
return val
except ValueError:
vals.append(-1)
return max(vals)
and it worked better than the previous solution but still failed to recognize some digits. Also, running 81*2=164 tesseract recognitions for every digit picture was painfully slow.

Sometimes, it recognized all of the digits; sometimes, it misinterpreted one of the cells, ruining the whole puzzle solution, and I had to give this idea up.
Model fitting
I had only one solution to try out. Fitting my initial data to digits I have in my precious puzzles. I created a bunch of screenshots and photos and put all of the digits square into a single directory and manually labeled them.
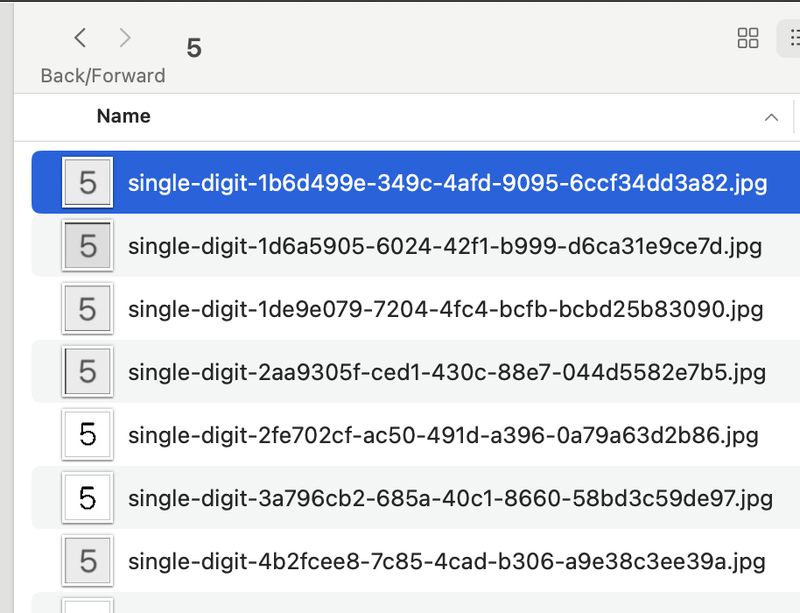
Then I took my saved model and fitted it (which is really easy to do!):
# Create a dataset of image and labels from the directory
train_dataset = tf.keras.utils.image_dataset_from_directory(
"for_fitting",
image_size=(28, 28),
color_mode="grayscale",
batch_size=32,
label_mode="int",
shuffle=True,
)
# Normalize pixel values to [0,1]
normalization_layer = tf.keras.layers.Rescaling(1.0 / 255)
train_dataset = train_dataset.map(lambda x, y: (normalization_layer(x), y))
model = tf.keras.models.load_model("mnist.keras")
# Fit the model on the new data
model.fit(train_dataset, epochs=10)
model.save("mnist-fit.keras")
I tried this out, and it worked. And again. And again. It was blazingly fast, with no errors, and solved my Sudokus with ease. The light of happiness touched my forehead, and I felt closer to God.
Telegram bot
The easiest part of it all was making a telegram bot and a Docker deployment for the whole solution. At this moment, the only issue was to make it all of the crazy libraries to install within the Poetry env in Docker, which I failed to do and just went with the Rye, which worked surprisingly well.

Outcomes
I felt stupid quite a lot during this endavour. I did not know anyting about the OpenCV, so my experience was mostly finding and copy-pasting the code. I understood logically its structure and steps to be done, but I don’t think I’d be able to reproduce it without the access to Google. I was shocked that the task of digit recognition was so, well, demanding in 2024.
I was also surprised with the direction the Python toolchain takes with all of the Rye and UV stuff in development.
I certainly enjoyed the experience and the time spent, and I definitely recommend everyone have a pet project that can be done from start to end in a week.
My solution is a toy one. It needs a ton of improvements and adjustments. I want to try Apple’s Vision framework to do this stuff in real-time via the Swift application, but that’s the story for another time!